LSTMについて
(いろいろなところでも解説されているように)LSTMはRNNの一種で、時系列データを扱う際に有効なモデル。 RNNでも過去の情報を保持することができるが、長期の依存関係を学習することが難しい。 また、勾配消失問題もある。
LSTMはこれらの問題を解決するために、過去の情報を保持するためのMemory Cellを導入している。
LSTMの構造
構造を理解するため図を自作してみた。
LSTMはこんな感じのLSTM Cellが複数重なった構造をしている。
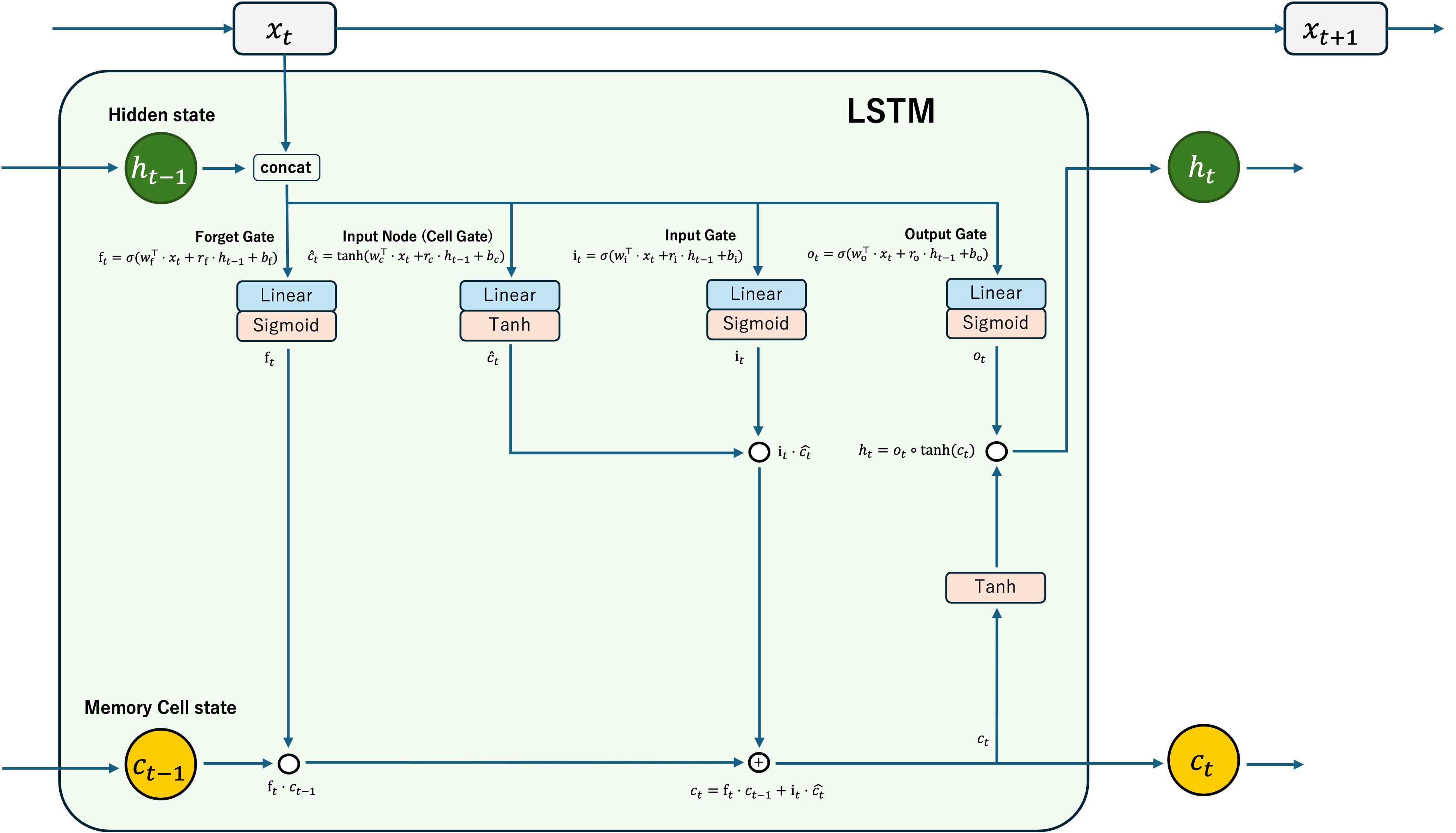
入力$x_t$のほかに、前の時刻の隠れ状態$h_{t-1}$とセル状態$c_{t-1}$が必要となる。
なので最初の入力には初期の隠れ状態が必要であり、よく$h_0$と$c_0$にはzeros(1, hidden_size)で初期化したものが使われる?
与えられた$x_t, h_{t-1}$ はそれぞれLinear層を通し、それらを足し合わせたものを活性化関数に通す。
ここのconcatの箇所は少し表現が怪しいものの、最終的に$x_t$と$h_{t-1}$の変換結果を足し合わせていることになっている。
入力はForget Gate(忘却ゲート), Input Gate(入力ゲート), Output Gate(出力ゲート)に通され、それぞれのゲートの出力とセル状態を更新するための値が計算される。活性化関数にはSigmoid関数が使われる。 その他に、セル状態を更新するために使う値$\hat{c_t}$を求めるためのCell Gateがある。ここは活性化関数にTanh関数が使われる。
Forget Gateではセル状態$c_{t-1}$の要素積を取り、入力から推測されたセル状態から忘れるべき情報を取り除く。(Sigmoid後は0~1の値、忘れ度合いみたいな感じ)
Input Gateではセル状態に追加する情報を計算する。この値は$i_t$として計算され、$\hat{c_t}$との要素積を取ることでセル状態を更新する。$i_t \cdot \hat{c_t}$は0~1と-1~1の値の要素積となり、これをセル状態に足し合わせることでセル状態が更新される。
Output Gateでは入力をどの程度次の隠れ状態に反映させるかを計算している。
次の隠れ状態$h_t$は、同時刻のセル状態$c_t$をTanh関数に通したものと、Output Gateの出力$o_t$との要素積を取ることで計算される。
PyTorchでの実装
PyTorchのnn.Moduleを使ってLSTMを実装してみた。引数が同じならばnn.LSTMを置き換えて使うことができる。(bidirectionalなどの引数は実装していない)
なるべくわかりやすく書いた。
なお、普通に使う分にはnn.LSTMを使うことをおすすめする。
速度が雲泥の差である。(本家はCUDAで実装されている?のかめちゃくちゃ速い)
各ゲートの計算を行うLSTMCellGatefromScratch
class LSTMCellGatefromScratch(nn.Module):
def __init__(self, input_dim: int, hidden_dim: int, activation: nn.Module = nn.Sigmoid()) -> None:
super(LSTMCellGatefromScratch, self).__init__()
self.input = nn.Linear(input_dim, hidden_dim)
self.hidden = nn.Linear(hidden_dim, hidden_dim)
self.activation = activation
def forward(self, x: torch.Tensor, hidden: torch.Tensor) -> torch.Tensor:
return self.activation(self.input(x) + self.hidden(hidden))
単純に2つの入力を受け取り、別々のLinear層を通し、それらを足し合わせたものを活性化関数に通す。
LSTM Cellの実装であるLSTMCellfromScratch
class LSTMCellfromScratch(nn.Module):
def __init__(self, input_dim: int, hidden_dim: int) -> None:
super(LSTMCellfromScratch, self).__init__()
self.input_size = input_dim
self.hidden_size = hidden_dim
self.forget_gate = LSTMCellGatefromScratch(input_dim, hidden_dim, activation=nn.Sigmoid())
self.input_gate = LSTMCellGatefromScratch(input_dim, hidden_dim, activation=nn.Sigmoid())
self.output_gate = LSTMCellGatefromScratch(input_dim, hidden_dim, activation=nn.Sigmoid())
self.cell_gate = LSTMCellGatefromScratch(input_dim, hidden_dim, activation=nn.Tanh())
def init_hidden(self, device: torch.device = torch.device("cpu")) -> tuple[torch.Tensor, torch.Tensor]:
return torch.zeros(1, self.hidden_size, device=device), torch.zeros(1, self.hidden_size, device=device)
def forward(
self, x: torch.Tensor, states: Optional[tuple[torch.Tensor, torch.Tensor]]
) -> tuple[torch.Tensor, torch.Tensor]:
"""
args:
x: torch.Tensor
The input tensor. / 入力tensor
states: tuple[torch.Tensor, torch.Tensor] = None
The initial hidden states. (hidden_state, cell_state) / 初期状態, Noneの場合は0で初期化
return:
tuple[torch.Tensor, torch.Tensor]
The output tensor and the final hidden states. (hidden_state, cell_state) / 次の状態
"""
if states is None:
states = self.init_hidden(device=x.device)
hidden_state, cell_state = states
f_t = self.forget_gate(x, hidden_state)
i_t = self.input_gate(x, hidden_state)
o_t = self.output_gate(x, hidden_state)
c_hat_t = self.cell_gate(x, hidden_state)
next_cell_state = f_t * cell_state + i_t * c_hat_t
next_hidden_state = o_t * next_cell_state.tanh()
return (next_hidden_state, next_cell_state)
上に載せた図の通りに計算していく。
LSTMの実装であるLSTMfromScratch
class LSTMfromScratch(nn.Module):
def __init__(self, input_dim: int, hidden_dim: int, num_layers: int, batch_first: bool = False) -> None:
"""
args:
input_dim: int
The input dimension. / 入力の次元数
hidden_dim: int
The hidden dimension. / 隠れ状態の次元数
num_layers: int
The number of layers / LSTM Cellの数
"""
super(LSTMfromScratch, self).__init__()
self.input_size = input_dim
self.hidden_size = hidden_dim
self.num_layers = num_layers
self.batch_first = batch_first
self.lstm_cells = nn.ModuleList(
[LSTMCellfromScratch(input_dim, hidden_dim)]
+ [LSTMCellfromScratch(hidden_dim, hidden_dim) for _ in range(num_layers - 1)]
)
def forward(
self, x: torch.Tensor, states: Optional[tuple[torch.Tensor, torch.Tensor]] = None
) -> tuple[torch.Tensor, tuple[torch.Tensor, torch.Tensor]]:
"""
args:
x: torch.Tensor
The input tensor. (seq_len, batch_size, input_dim) or (batch_size, seq_len, input_dim) / 入力tensor
states: tuple[torch.Tensor, torch.Tensor] = None
The initial hidden states. (hidden_state, cell_state) / 初期状態, Noneの場合は0で初期化
return:
tuple[torch.Tensor, tuple[torch.Tensor, torch.Tensor]]
The output tensor and the final hidden states. (output, (hidden_state, cell_state)) / 出力tensorと最終状態
"""
if states is None:
states = self.lstm_cells[0].init_hidden(device=x.device)
if self.batch_first:
# (batch_size, seq_len, input_dim) -> (seq_len, batch_size, input_dim)
x = x.permute(1, 0, 2)
sequence_length = x.size(0)
# 隠れ状態とセル状態の初期化,
# x = [x0, x1, ... xn]からoutput = [x1, x2, ..., xn+1]
# のように次を予測していくため長さはsequence_length+1
hidden_states, cell_states = [None] * (sequence_length + 1), [None] * (sequence_length + 1)
hidden_states[0], cell_states[0] = states # initial hidden states
for t in range(sequence_length):
# LSTM Cellの計算, 入力はx[t, :], 前の状態はhidden_states[t], cell_states[t]
hidden_states[t + 1], cell_states[t + 1] = self.lstm_cells[0](x[t, :], (hidden_states[t], cell_states[t]))
for i in range(1, self.num_layers):
# 複数層の場合は前の層の出力を次の層の入力として使う
hidden_states[t + 1], cell_states[t + 1] = self.lstm_cells[i](
hidden_states[t + 1], (hidden_states[t + 1], cell_states[t + 1])
)
# 初期状態を除いたhidden_states[1:]と隠れ状態を返す
output = torch.stack(hidden_states[1:]).to(x.device)
if self.batch_first:
output = output.permute(1, 0, 2)
return output, (hidden_states[-1], cell_states[-1])
LSTMが動くか確認
PyTorch公式のチュートリアルにある例を使って、LSTMが動くか確認してみる。
# %%
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 実装省略
class LSTMCellGatefromScratch(nn.Module):
...
class LSTMCellfromScratch(nn.Module):
...
class LSTMfromScratch(nn.Module):
...
torch.manual_seed(1)
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
training_data = [
("The dog ate the apple".split(), ["DET", "NN", "V", "DET", "NN"]),
("Everybody read that book".split(), ["NN", "V", "DET", "NN"]),
]
word_to_ix = {}
for sent, tags in training_data:
for word in sent:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
print(word_to_ix)
tag_to_ix = {"DET": 0, "NN": 1, "V": 2}
EMBEDDING_DIM = 6
HIDDEN_DIM = 6
class LSTMTagger(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):
super(LSTMTagger, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
# self.lstm = LSTMfromScratch(embedding_dim, hidden_dim)
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
lstm_out, _ = self.lstm(embeds.view(len(sentence), 1, -1))
tag_space = self.hidden2tag(lstm_out.view(len(sentence), -1))
tag_scores = F.log_softmax(tag_space, dim=1)
return tag_scores
model = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix))
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
with torch.inference_mode():
inputs = prepare_sequence(training_data[0][0], word_to_ix)
tag_scores = model(inputs)
print("before training | expect 0 1 2 0 1")
# print(tag_scores)
print(tag_scores.argmax(dim=1)) # 学習前はランダムなので正解とは限らない
for epoch in range(300):
for sentence, tags in training_data:
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = prepare_sequence(tags, tag_to_ix)
tag_scores = model(sentence_in)
loss = loss_function(tag_scores, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.inference_mode():
inputs = prepare_sequence(training_data[0][0], word_to_ix)
tag_scores = model(inputs)
# The sentence is "the dog ate the apple". i,j corresponds to score for tag j
# for word i. The predicted tag is the maximum scoring tag.
# Here, we can see the predicted sequence below is 0 1 2 0 1
# since 0 is index of the maximum value of row 1,
# 1 is the index of maximum value of row 2, etc.
# Which is DET NOUN VERB DET NOUN, the correct sequence!
print("after training | expect 0 1 2 0 1")
# print(tag_scores)
print(tag_scores.argmax(dim=1)) # 0 1 2 0 1になっていれば正解
# %%
nn.LSTMではもちろん動く。
上に記載したLSTMの実装を貼り付け、LSTMTagger内のself.lstmをself.lstm = LSTMfromScratch(embedding_dim, hidden_dim)にしても動くはず。
参考